Seznam.cz pro shrnutí článků a diskusí využívá vlastní AI
Seznam.cz rozšiřuje využívání vlastního nástroje umělé inteligence. Nově díky němu shrnuje články na home page nebo témata v diskuzích.
Zdroj: Seznam.cz
Seznam.cz nabízí na své domovské stránce nové AI funkce využívající velké jazykové modely (LLM). Patří mezi ně možnost zobrazit shrnutí článku bez jeho otevření, přehled nejdiskutovanějších témat v diskuzích a vysvětlení, proč konkrétní dotazy trendují v Seznam.cz Vyhledávání. Seznam.cz k tomu využívá vlastní velké jazykové modely s názvem SeLLMa, které se učí na českém korpusu.
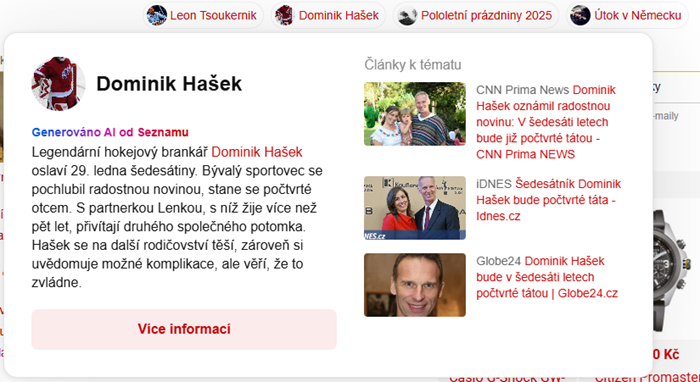
Jednou z vizuálně nejvýraznějších novinek na domovské stránce je možnost zobrazit shrnutí článku, aniž by ho uživatel otevíral. Jazykový model přečte článek a připraví z něj krátké shrnutí, které se zobrazí po umístění myši vedle titulku článku. Tato funkce je v současné době k dispozici pouze na desktopových zařízeních.
„Na možnosti zobrazit shrnutí článku s pomocí AI jsme pracovali více než rok. Samo o sobě to není pro SeLLMu složitý úkol, ale zajistit, aby vše fungovalo automaticky bez zásahu editora a přešlapů běžně spojených s generativními modely, bylo složitější,“ říká Marek Vacek, produktový manažer domovské stránky Seznam.cz.
Další funkcí jsou „Top narativy“– přehled nejdiskutovanějších témat, které vytváří umělá inteligence na základě uživatelských komentářů pod článkem. Díky sumarizaci nejčastějších úhlů pohledu získají uživatelé přehled o tom, co rezonuje v konkrétní diskuzi i přibližný obraz o náladě a postojích diskutujících, aniž by museli pročítat desítky či stovky komentářů.
Mezi nové funkce patří také „Trending topics s vysvětlením“. Pod vyhledávacím polem vyhledávače nabízí trendující dotazy, které získává ze Seznam.cz Vyhledávání a nově poskytuje uživatelům i vysvětlení, proč je o daný dotaz zájem. Najde aktuální články na dané téma a pomocí velkých jazykových modelů vygeneruje z obsahu těchto článků důvod náhlého zvýšení počtu hledání.
„Náš nejnovější model v produkci SeLLMa, vycházející z open-source modelu Llama 3.1, má 70 miliard parametrů. Doučujeme naše modely na velkém korpusu českých textů, které máme k dispozici, učíme ho českým formulacím, gramatice a důraz klademe i na bezpečnost,“ dodává Diana Hlaváčová, produktová manažerka velkých jazykových modelů.
-mav-
Tagy

